Delivery that understands your stack
The real slowdown in delivery isn't one rebuild, it's every change crawling through slow release cycles with messy dependencies. You can't see other setups, Lifecycle is unclear, The code turns into technical debt fast. No one wants to touch it. You have to read too much before using it. Every tweak means rebuilding the same foundations across every pipeline. With Ankra, a few calls replace all that. With the Ankra Platform, your release cycles will be cut by up to 90 percent.
What Ankra does
Ankra treats delivery as a graph problem, not a scripting problem. The moment a resource enters the system, it gets a lifecycle. We keep a strict DAG of dependencies and update only what changed, in the right order, and in parallel where it is safe. Validation and readiness live with the resources, not in scattered scripts. Because the engine knows order and health, you are not writing custom waits and retries. In practice, the hand written job count falls sharply.
AI Assistant in the platform
The AI assistant helps DevOps design stacks with clear guardrails and immediate feedback on order, health, and impact. Developers can see what the platform team configured, understand why, and resolve customizations or small fixes themselves without waiting on DevOps. Technical managers and security officers, validate posture and policy, compare environments, and understand lifecycle timing without extra permissions. The AI assistant explains dependencies and requirements in plain language and links back to the nodes in the graph. All in one platform.
How it fits your workflow
Most teams keep their current tools and change the shape of the work.
- Package the app with Docker and Helm, push to your registry and repo.
- Connect your Git repository and credentials so the engine can write back.
- Import the Helm chart into Stack Builder and map dependencies like DB, cache, ingress, and observability.
- Preview the plan, then deploy. The engine runs the lifecycle and commits results to Git.
- Operate through Git, Terraform, CLI, or API as needed. Same engine, same rules.
- Spin up a new environment by copying the stack folder, adjusting inputs, and committing. Minutes, not days.
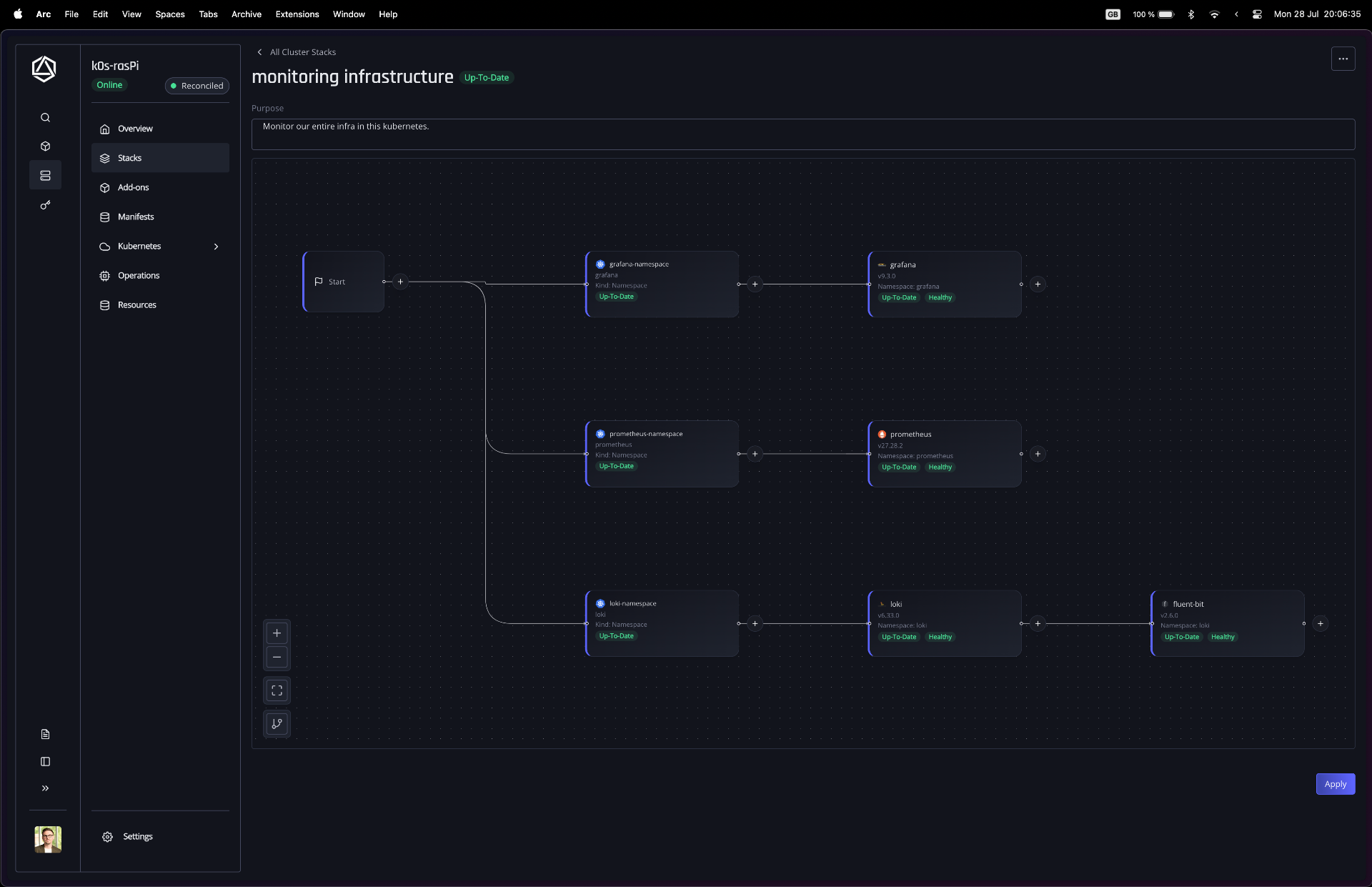
Impact in practice
In customer and users work, we see large drops in effort and lead time because the engine absorbs the choreography and runs only what is needed. Pipeline builds shrink because order, waits, and checks come from the graph instead of hand written jobs. Teams report fewer blocked by DevOps, as developers import Helm, assemble stacks, preview plans, and deploy without waiting on DevOps approval or TicketOps. Convergence is faster because only changes are isolated and safe paths run in parallel. When a provider cannot do partial updates, the engine narrows the blast radius so unrelated resources do not restart. Developers can become capable to solve problems and configurations themselves, while managers and security validate live setups without cluster credentials.
- Fewer deliver blockers, more time on product work.
- Faster path from idea to merge to running service.
- Fewer rollbacks and narrower incidents, which lowers the cost of change.
Next-generation optimization
Changing configs in Kubernetes shouldn't be a slow, painful process. With live feedback, instant edits, and context-aware assistance, you can tweak settings and see the results in the dependency graph immediately. No waiting on long deploy cycles just make the change, watch it update, and keep moving. It s built for speed, for experimenting, and for getting deployments exactly right without the guesswork. This is DevOps in real time. Fine tune in the fastest way possible, roll out when its ready, all from one platform.
Git as the source of truth
Every action the engine takes is written to your repository. You get history, diffs, pull request reviews, and rollbacks without inventing conventions. It is clean for machine to machine automation: systems can read one repo, produce signed commits, open pull requests, and let policy engines approve or reject based on code and context. You see who changed what, when, and why, and you can link each change to tickets and releases. Collaboration improves because product, security, and operations share the same record. Reviews speed up, audits take hours instead of days, and incident timelines are easier to reconstruct. UI and Git stay aligned. If you click in the UI, the engine still writes to Git. If you commit in Git, the engine reconciles the same way. One system. One truth.
A minimal, single manifest and single addon example. Simple, readable, and ready to drop in.
1apiVersion: v1
2kind: ImportCluster
3metadata:
4 name: imported-cluster
5 description: Simple example with one manifest and one addon
6spec:
7 git_repository:
8 provider: github
9 credential_name: <github credential id>
10 branch: <main>
11 repository: <username>/<gitops repository>
12 stacks:
13 - name: monitoring
14 manifests:
15 - name: grafana-ns
16 from_file: manifests/grafana-ns.yaml
17 addons:
18 - name: grafana
19 chart_name: grafana
20 chart_version: 9.2.10
21 repository_url: https://grafana.github.io/helm-charts
22 namespace: grafana
23 configuration_type: standalone
24 configuration:
25 from_file: add-ons/grafana/values.yaml
26 parents:
27 - name: grafana-ns
28 kind: manifestWhat this replaces
If you have maintained delivery YAML, you know the bloat. Wait loops because readiness is hard to observe. Custom sequencing because dependency order is implicit. Duplicate validation because the job runner cannot see your resources. Retries without context. Ankra absorbs that work. Health and readiness are native. Order comes from the graph. Validations run where the resource lives. Retries happen with context. The day to day effect is fewer moving parts to babysit and more time spent on product work.
Repeatability and safety
Build an environment once and it's easy to clone it, evolve it, or retire it cleanly. Because the plan is derived from the same DAG every time, you get deterministic outcomes from the same inputs. That holds in the UI, a commit, Terraform, the CLI, or an API call. The surface area for error shrinks, rollbacks are clean, and change failure rate trends down as you replace ad hoc scripts with a system that understands dependencies.
The backbone
A strict DAG gives safe parallelism, predictable sequencing, and clear failure domains. It also lets us decide what not to touch while still landing your change. That restraint is where much of the speed up comes from. Fewer components restarted. Fewer paths for things to go sideways. Less rework after the fact.
Related Posts
A practical guide to wiring an infrastructure agent into your CI: review comments on pull requests, deploy verification on merge, and Slack reports that contain an actual root cause instead of a red X.
Kubernetes on the Edge: One Platform to Rule Them All
Edge Kubernetes is exploding, but our operational tooling has not kept up. Here is how Ankra delivers a true single pane of glass combining AI-powered troubleshooting, native GitOps, and stack cloning to turn weeks of cluster setup into minutes.